
Regardless of the licence purchased, MOVEit Automation has a set of prebuilt scripts that are available straight out of the box for all users. One of the most underused of these is the Lookup process, which can greatly extend the capabilities of Automation.
This process allows you to take a piece of information and use it as a comparison key against a CSV file; at the completion of the process, one or more values can be returned which you can then utilise in your workflow.
How does the MOVEit Automation Lookup Process Work?
The comparison key being passed is often (but not necessarily) a filename (in the form of a macro) – this will generally result in a folder name being returned. This allows an administrator to dynamically set the destination folder based upon the name of the file. You can get a similar effect with an advanced task, however, because you can easily add all the entries you wish into the lookup CSV, it’s much tidier when compared to using multiple if statements. In addition, a CSV file is something that business users can understand and provide to an administrator for immediate implementation.
One consideration to bear in mind however is that the comparison occurs on a line-by-line basis, starting at the top of the lookup file. This means that if you do have a lot of entries in the file, potentially MOVEit may use extra memory, reading unnecessary lines until it reaches the one that it needs.
How to use the MOVEit Automation Lookup Process
Let’s take a technical look at the process. First, you should note that the process can be run against either the whole script or each file. In general, this will be each file, but remember that in some circumstances you may need to make a comparison against a task level macro; for example, imagine a backup task where the destination location is dependent upon the day of the week. Incidentally, in the case of needing to backup a different source each day, you could run the lookup as the first step of an advanced task, prior to downloading any files.
The script has five required parameters which must be completed:
- LookUp_ActionIfKeyNotMatched:
- This determines whether the process should end in error, or not, in the event of no match being found in the Lookup file
- LookUp_FilePath:
- The full path (including filename) to the Lookup file
- LookUp_Key:
- The piece of information that is passed to the Lookup process is generally a macro (for example [OrigName] for the file name).
- LookUp_MatchType:
- Selects how to compare the key to the entries in the file. This can be an exact match, a partial match to the key being passed, or a partial match to the entry in the file.
The values returned can be accessed using macro [PARM:Lookup_Value] for the first field, [PARM:Lookup_Value2] for the second etc. Often this will be used in a destination host in place of a filename, folder or email address.
Incidentally, the name “Lookup_Value” can be changed using the optional parameter LookUp_ReturnAs; this is useful if you need to use two different LookUp processes in a task.
Something that often throws people is the LookUp_MatchType parameter. Here is an example lookup file with an accompanying set of parameters:

You’ll notice that although the first two lines contain an actual word as the first column (the key), the third and fourth lines contain a wildcard. This would require you to use ‘Allow Partial Match of File Keys’; it would return the following values according to these keys:
- red = red_folder
- green = green_folder
- blue = blue_black_brown_folder
- yellow = other folder
However, if you switch it to ‘Allow Partial Match of Lookup Key’, only red and green would work, and lines 3 and 4 would return an error – this is because it does not expect the lookup file to contain a wildcard, instead it expects the wildcard to be in the task (for example, you could supply re* as a value in lookup_key and get a match against ‘red’ in the csv). Finally, setting the lookup_MatchType to ‘Require_Exact_Match’ means no wildcards at all.
Combining the Lookup Process
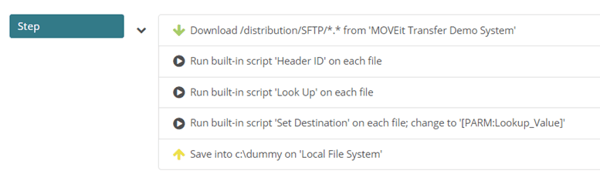
The lookup process comes in especially useful when combined with other processes. For example, consider the following task:
These parameters are set:
- HeaderID_Length 8
- HeaderID_Start 1
- HeaderID_Strip No
- LookUp_ActionIfKeyNotMatched Throw_Error
- LookUp_CaseSensitive No
- LookUp_FilePath c:\richard\lookup.txt
- LookUp_Key [Parm:HeaderID_Value]
- LookUp_MatchType Require_Exact_Match
- SetDestination_Host [Parm:Lookup_Value]
- SetDestination_IgnoreError No
- SetDestination_Path [Parm:Lookup_Value2]
In this instance, a file will be collected which contains a reference in its header to the server to which it is supposed to be delivered. The task reads the header information in the first process and passes the reference to the Lookup process using [Parm:HeaderID_Value].
The lookup process locates the row containing the destination server reference and returns two values – the server ‘friendly’ name as it is known to MOVEit Automation, and the path in the server where the file is to be delivered to.
The third process takes that information and dynamically changes the destination server and directory – the c:\dummy local system reference is replaced by the new values.
Finally, it’s worth mentioning the following scenario:
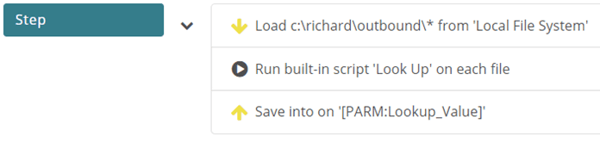
You can potentially reduce the number of UNC definitions in Automation by having a generic UNC host and setting the destination in a task by using the Lookup Process. However, if you decide to try this, you need to be aware that MOVEit will try to connect to the host at service startup – this will delay the startup of task processing. As a reminder, you will see the following error when defining the host:

As experts in this space, we are here to help. We have assisted with over 1000 MFT projects over 18 years. If you want to know more about getting the most out of MOVEit Automation or have questions about the Lookup process, please get in touch with us.
|
About the Author:
|


