
The limitations of Microsoft Excel have been blamed for the glitch that led to nearly 16,000 cases of COVID-19 going unreported in England. Our experts explain what a better setup would look like.
The process as we know it
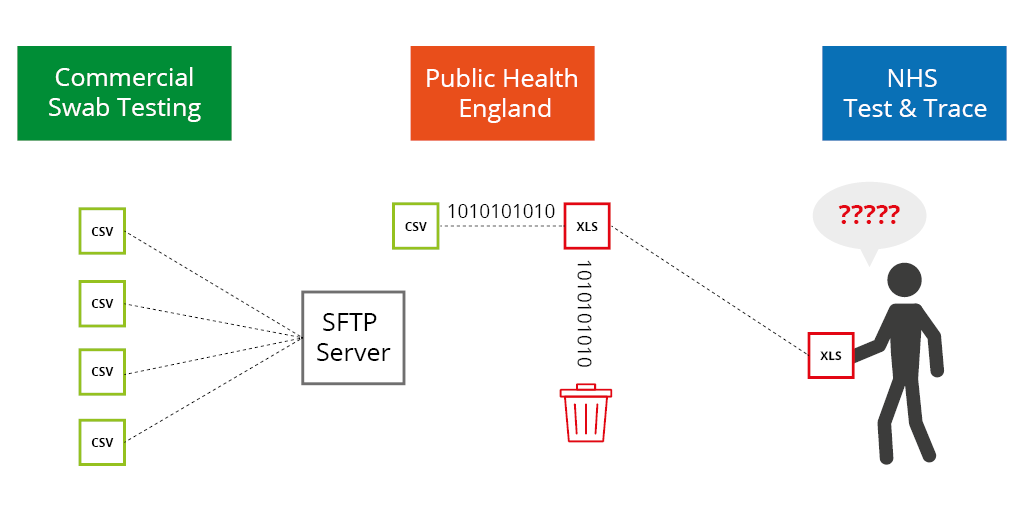
Commercial firms analysing the COVID swab tests filed their results in CSV format without problem. These were sent to Public Health England (PHE) by their preferred method, SFTP1. There were no reported problems here.
Multiple files from multiple locations were received by PHE, then processed and consolidated into a single file in order to “upload to NHS Test & Trace team as well as other government computer dashboards,” according to the BBC2. This shouldn’t be a complex process, but this is where the problems began.
The cause
PHE developers selected an inappropriate file type to process potentially large volumes of data. Selecting Microsoft Excel’s XLS format allows a maximum number of rows just north of 65.5k. With complex test results taking many rows, only around 1,400 cases could be stored in each file. The rest of the data simply wasn’t retained.
What should have been in place?
Richard Auger, Pro2col’s Technical Manager, says, “It’s well known that the XLS format is inferior to CSV, and it’s therefore so infrequently used that we haven’t created a workflow based on this format for at least ten years.”
Given that PHE were central to the Government’s estimation on 21st September that “cases could reach 50,000 by October,” it’s not unreasonable to expect systems and processes to have been built with this volume in mind, or at the very least, with scalability in mind3.
The biggest issue is that the process design was fundamentally flawed. Any critical process such as this, should have had some error handling and reporting capabilities built into it. James Lewis, Managing Director at Pro2col suggests, “Taking eight days to identify the problem is unreasonable, and unnecessary. There are a number of ways basic error handling mechanisms could have been built into their workflow processes that wouldn’t have impacted performance design.”
What should have been in place?
To handle data movement of this scale, the process should include:
- Security controls – Test results are classified as personal, sensitive data.
- Automated onward processing – This might include results alerts, moving to the Test & Trace team, and reporting.
- Reporting / error handling – The governance of sensitive data is critical, even more so in this case.
So what would a better setup look like?
The supply of data to PHE appears to be without fault – structured data in CSV files, provided by a secured file transfer protocol, SFTP.
The CSV files were then presumably processed automatically. The contents of each CSV exported and written to the XLS file. This is where the error most likely occurred, and could have been avoided.
Whilst we don’t know what other steps might have existed in their process, it is possible to select multiple CSV files and merge into a single CSV file. This would offer much larger capacity and ensure that all data is imported.
There are also several steps that could be incorporated to mitigate risk:
- A check on the file creation date to ensure that only the correct files were being processed would be the first step.
- Error handling can take many forms. A simple process would be to read the number of lines of data contained in each CSV file, total the number of records across all files, and match that against the output file. The result? A mismatch is quickly identified and action can be taken to resolve it before, it makes an impact. This would also allow any receiving party to check the governance of the data received before delivering it to any onward process.
- Uploading an XLS file to the NHS Test & Trace team would likely result in a more complex routine for extracting the data than if it was provided in CSV format, which is much easier to import into onward systems.
Summary
As practitioners of workflow best practice, we’d guess that whoever designed and delivered this process had limited experience of creating workflows, especially for such critical healthcare data. The technology wasn’t at fault. It was the lack of insight to build in error reporting, combined with the failure to test the process with the volume of data they’d been expecting for many weeks. This was an entirely avoidable situation, and not a particularly complicated process to implement correctly.
References



Take the risk out of selecting an MFT solution with our free, independent comparison service!
Our comparison report identifies the right solution for your needs and budget. Complete a series of questions and receive a bespoke product recommendation from our technical experts.