
Understand
Managed File Transfer Software
The A to Z of MFT - features, history, key terms, marketplace, leading vendors and more...
Introduction
The History of MFT
Although organisations had been securing and automating the exchange of data prior to 2008, it was at this point that the term Managed File Transfer was coined. Frank Kenney of Gartner Inc. used it as a common description for a collection of solutions. Gartner went on to monitor this technology under the umbrella term of Managed File Transfer for a couple of years. They used their widely acclaimed Magic Quadrant to rank vendors based upon vision and ability to execute, and the functionality afforded by the products they offered.
The first iteration of the Magic Quadrant included a number of vendors and products that wouldn’t be deemed to fit the definition of MFT today. But as a starting point it highlighted a wide range of organisations providing secure file transfer. An analysis of the vendors listed in Gartner’s 2009 Magic Quadrant, now 15 years old, can be found here. Gartner’s initial sweep of the market included vendors which now operate in different technology stacks such as: File Synchronisation & Sharing (EFSS), Electronic Data Interchange (EDI), Extreme File Transfer, Content Collaboration Platforms and Workload Automation.
What is Managed File Transfer (MFT)?
In today’s business environment the majority of operations involve the movement of data. This is most often the transfer of files. Examples include processing retrieved orders from e-commerce stores, uploading customer data into a SaaS CRM or transferring documents between colleagues, computers and applications.
Managed File Transfer solutions allow file transfers to take place in a centralised, controlled, secure fashion – inside and outside an organisation – between systems and / or users. Files are transferred more quickly and securely, enhancing productivity and providing visibility. It is a powerful business enabler that reduces costs and risk. Managed File Transfer is commonly installed to replace legacy or homegrown scripts, improving efficiency, agility and cost-savings through automation, and opening the door to new digital transformation, cloud and big data initiatives.
Traditionally, solutions are on-premise software installations, enabling tight integration with internal systems. However, hybrid configurations are increasingly common as organisations look to leverage the private cloud infrastructure for operational efficiencies. Now, cloud-first solutions are growing in maturity, providing full control over data and workflows without the infrastructure management.
Benefits of Managed File Transfer (MFT)
Secure managed file transfer of data is essential for protecting sensitive data. Without a reliable MFT solution, organisations risk security breaches, compliance violations, reputational damage, and substantial financial penalties.
Implementing a robust Managed File Transfer solution helps businesses overcome these challenges by providing secure, efficient, and automated data transfers. MFT not only ensures that files are transferred securely but also provides an essential audit trail, allowing businesses to track every exchange. This level of control and visibility is crucial for maintaining compliance and protecting data integrity.
There are several key benefits of implementing a Managed File Transfer solution, including:
Data Security
Secure MFT software significantly enhances the security of data transfer through real-time monitoring and robust end-to-end encryption, utilising secure protocols such SFTP, FTPS, HTTPS, and AS2 to protect files both in transit and at rest. A reliable file transfer solution is essential for all organisations, but especially in highly regulated industries, especially in sectors like healthcare, where safeguarding the processing of sensitive patient data is paramount. Or in the Finance sector, where you have secure sensitive records, transactions and account details, and similarly in the legal field, where there is confidential case files and legal documents between law firms, clients, and courts.
MFT platforms also offer centralised management, allowing administrators to configure user roles, permissions, and access controls.
Regulatory Compliance
In highly regulated industries such as finance, healthcare, and defence, the integration of Managed File Transfer (MFT) software plays a crucial role in maintaining data confidentiality and meeting strict compliance standards. Secure file transfer solutions help organisations adhere to regulations such as the General Data Protection Regulation (GDPR), Health Insurance Portability and Accountability Act (HIPAA), the Sarbanes-Oxley Act (SOX), and Payment Card Industry Data Security Standards (PCI-DSS). These regulations impose rigorous data security requirements all of which are core capabilities of modern MFT solutions.
Reduced Costs and Increased Efficiency
Managed File Transfer (MFT) software significantly reduces IT overhead and operational costs by automating time-consuming file transfer workflows. By eliminating the need for manual intervention, MFT streamlines the process of transferring data securely, freeing up valuable IT resources that would otherwise be spent on handling routine tasks.
When we consider the retail and logistics industry for example, MFT can automate the daily transfer of purchase orders, invoices, and shipping notifications between warehouse management systems, suppliers, and distribution centres. This ensures real-time visibility into order status and stock levels, improving accuracy and helps organisations manage their inventory more effectively and respond to demand faster.
This automation of file transfers not only saves time and minimises the risk of human error, but also leads to greater operational efficiency, reduces costs and allows businesses to scale more efficiently as demand grows.
Visibility and Auditability
Enterprise File Transfer software provides businesses with enhanced visibility and auditability features that help track, manage and protect their most sensitive data - an essential part of maintaining a Zero Trust security posture and keeping track of your vital IP.
With real-time monitoring of file transfers, organisations have insight into the status and progress of every data transfer. This visibility allows teams to proactively identify and address issues such as failed transfers, delays, or any anomalies before they escalate into larger problems. For example, a team can receive an alert that a critical financial report transfer to a partner has failed, prompting immediate troubleshooting to ensure the document reaches its destination securely without further delay. Moreover, with detailed logs and audit trails, businesses can track who initiated each file transfer, who accessed the data, and when the transfer occurred.
Integration with Existing Systems
Another key benefit of Managed File Transfer (MFT) is its ability to connect seamlessly within an organisation’s existing IT ecosystem. By integrating with core business systems such as SharePoint, Salesforce, AWS, Microsoft Azure, and Google Drive, MFT enables faster, more reliable data exchanges across departments and partners. This interoperability eliminates silos, reduces manual effort, and ensures that critical files flow securely and efficiently between the systems teams rely on every day.
Common Features of MFT
Managed File Transfer technology has evolved significantly from its origins as a simple solution for processing incoming and outgoing SFTP transfers. Today, MFT systems support increasingly complex workflows, deployment across hybrid environments, and cloud infrastructure. Enterprise managed file transfer solutions also support a broader range of file transfer secure protocols, making them adaptable to various business needs.
File Transfer Protocols Supported by MFT
- FTP – file transfer protocol
- FTPS – FTP over SSL
- SFTP – FTP over SSH
- SCP – secure copy protocol
- OFTP – Odette FTP
- HTTP/S – Hypertext Transfer Protocol / Secure
- ASx – Applicability Statement Protocols
- POP3/IMAP – Post Office Protocol and Internet Message Access Protocol
- WebDAV/S – Web Distributed Authoring and Versioning
Core Features of MFT Solutions
Encryption: Secure managed file transfer software uses robust protocols - such as SFTP, FTPS, HTTPS, and AS2 - along with strong encryption algorithms like AES, RSA, and PGP Encryption to ensure that data is securely encrypted both in transit and at rest, protecting files from unauthorised access and malicious actors.
Automated File Transfers: MFT solutions can automate file transfer workflows to improve efficiency. Users can schedule transfers at specific times, or trigger transfers based on defined events, adjust data as part of the workflow - renaming files, applying naming conventions, removing unnecessary data, and perform other pre-processing tasks, eliminating manual intervention and ensuring timely and accurate file delivery.
Centralised Management: Managed File Transfer software provides a centralised console for managing all file transfers. This makes it easier for IT teams to track, monitor, and control file transfer activities across the business, ensuring greater oversight, streamlined operations and removes the risk of Shadow IT by eliminating the need for unapproved or ad-hoc file sharing tools.
Audit Trails:Comprehensive audit trails are a key feature of enterprise file transfer, providing a detailed log of file transfer activity. These logs track who transferred which files, when, and where, ensuring full traceability and accountability.
Managed File Transfer Integration with Existing Systems: Managed File Transfer solutions for businesses are designed to seamlessly integrate with an organisation’s existing systems, core business applications and endpoints. Integration is often achieved through APIs and pre-built connectors, enabling smooth interoperability with systems such as SharePoint, CRM systems (Salesforce), ERP platforms (SAP, Oracle), cloud services (AWS, Microsoft Azure, Google Drive), and internal databases or file servers.
Compliance Support: MFT solutions help organisations meet strict regulatory requirements such as HIPAA, PCI DSS, and GDPR by ensuring secure data transfer and maintaining audit trails.
Who Uses MFT?
Almost all businesses, from global enterprises to highly regulated industries need Managed File Transfer for their secure data exchange processes between with business partners, suppliers and customers. Whether it’s customer information, financial data, healthcare records, or supply chain documents, MFT solutions provide a secure, reliable and scalable solution for protecting sensitive data in transit.
As organisations deal with growing demands for compliance, automation, or complex integrations, MFT is a critical tool across industries and teams.
Industries that Rely on Managed File Transfer
Finance and Banking: MFT secures the transfers of financial data, account information, statements, and transaction files while meeting strict regulatory requirements like PCI DSS, SOX and DORA.
Healthcare: MFT plays a critical role in moving and securing sensitive and personal data, including patient records, lab results, and insurance information, while also helping organisations comply with strict data privacy requirements such as HIPAA and GDPR.
Retail: Automate inventory updates, share sales data, and exchange customer information between points of sale, warehouses, and e-commerce platforms with a secure file transfer solution, optimising supply chain management.
Government and Public Sector: Government and public sector entities handle vast amounts of highly sensitive personal data, often more so than any other industry. MFT enables secure, encrypted data transfer exchanges between departments, agencies, and external partners, while maintaining full audit trails. With growing threats from cyberattacks and nation-state actors, MFT is vital in protecting public data.
Manufacturing & Logistics: MFT connects suppliers, distributors, and carriers by securely transferring essential data, such as shipment details, delivery confirmations, and inventory updates. While MFT doesn’t harness the power to control physical deliveries, it underpins the technology that does.
Enterprise Businesses: While specific industries have unique needs and we’ve only touched on a few, the reality is that almost every organisation relies on secure file transfer. For enterprise businesses, managing large volumes of sensitive data is part of daily operations. Whether it's sharing intellectual property, managing payroll and HR records, or financial data, MFT helps enterprise businesses protect sensitive information while keeping core operations running smoothly. Data transfer solutions integrate easily with existing disparate business systems. From your CRM systems like Salesforce, to ERPS such as SAP and Oracle, and cloud platforms like Microsoft Azure or AWS. MFT for enterprise businesses also supports secure file transfer across departments, satellite offices and international teams - no matter where they're located.
Many industry sectors and indeed countries are subject to specific legislation governing how data should be handled and protected. Some key compliance frameworks supported by Managed File Transfer include:
- Payment Card Industry Data Security Standard (PCI DSS)
- Sarbanes Oxley (SOX)
- Health Insurance Portability and Accountability Act (HIPAA)
- General Data Protection Regulation (GDPR)
- Digital Operational Resilience Act (DORA)
- Gramm-Leach-Bliley Act (GLBA)
Leading Enterprise
File Transfer
Software Solutions
I’m sure you’ll appreciate this isn’t an easy question to answer simply because it depends on what you’re looking for. Most products offer the same functionality but vary in how they deliver it. The best product for you is going to depend entirely on your unique business requirements. This level of detail will make all the difference. That’s why it is so important to fully scope your current and future business needs and take all stakeholders into account. You don’t want to make an expensive mistake.
If you speak directly to the vendors remember one thing – the Salesperson can ONLY sell their product, so inevitably each will tell you their solution is the best! To find the right Managed File Transfer solution for your needs, visit our Managed File Transfer comparison for independent expert advice.

Get a Full View
of the MFT Marketplace
What are the top MFT Solutions
to consider in 2025?

Alternatives to MFT
We have helped more than a thousand businesses secure and automate their file exchanges. Yet as much as we love MFT technologies, it absolutely isn’t right for every company or every use case.
Over the last decade, file transfer solutions have fragmented into different categories. This means there is some overlap. That includes: Enterprise File Synchronisation & Sharing (EFSS), Electronic Data Interchange (EDI), Content Collaboration Platforms, among others.
In fact, there are a surprising number of other technologies that provide a degree of file transfer automation. Some do it well even though it’s not part of their core offering. Others don’t.
Over the years we’ve reviewed and replaced a wide range of technologies, documenting which features differentiate them from MFT and which overlap. If you’re considering any of these, the extra information in the links provide some clarity during your decision-making process.
The Future of MFT
Over the past ten years, companies large and small have been jumping on the ‘digital transformation’ band-wagon. Yet digital transformation initiatives have a terrible failure rate; over 70% according to global consulting firm, McKinsey.
Why? Well, there are many reasons. Often the scope is too huge, so when it comes to actually breaking down what the business is doing and delivering it, the task is just too large.
In our experience the most successful Managed File Transfer projects have been at a more tactical level. We have long harboured the view that the ‘project’ should be elevated to address more data flows than a customer is currently looking to solve. With hindsight, however, success is mostly achieved by doing one thing really well and then and only then, looking at how the solution can expand to address other use cases. We expect to see companies expanding the reach of their solution as they get a better understanding the true value MFT delivers.
Additionally, we’ll see more hybrid deployments, encompassing on-premises and public/private cloud infrastructure. Connectivity will also be extended further. Robust REST and SOAP APIs are already providing the capability for Managed File Transfer solutions to either drive or be driven by external applications.
It is likely we’ll see further consolidation in this marketplace, with more mid-sized players being snapped up for their customer base to the detriment of the MFT users. It’s happened a number of times in the 20+ years we’ve been working in this space, and it will happen again.
With Managed File Transfer tools forming the backbone of business operations, a significant trend shaping the future of MFT is the growing demand for complete, real-time visibility of file transfers through one centralised dashboard. More businesses are adopting advanced MFT Dashboarding and Analytics tools that provide a "single pane of glass" view into all their file transfer activities, giving them unparalleled insights and greater control of their solution.
How Much Does MFT Cost?
The price of a potential Managed File Transfer solution depends entirely on your requirements, business size and the functionality you opt for. But we can give you an idea, based on products we recommend to our customers. Costs for a simple, yet capable automation solution for a business with a limited number of requirements starts at around £3000, plus £600 per year for a support contract. From there, a solution price might scale based upon a number of metrics. Not all software vendors follow the same model, but all currently apply:
- Single server
- Multiple servers for high availability
- Disaster recovery licenses
- Development, Test, User Acceptance Testing licenses
- Number of trading partners – a model adopted by some
- Modules – the features you require can make a big difference
- Proxy servers and load balancers
- Reporting modules or dashboards
- File sharing and collaboration users (where appropriate)
- Number of processes that can be run concurrently
Most MFT solutions fall into the £10,000 – £50,000 range, however, we’ve implemented solutions at three times that amount too. Support contracts are typically 20-30% of the licence cost per year, unless you’ve opted for a subscription where support is rolled into the overall annual cost. As you can see there are lots of variables and it’s not always easy to compare solutions on the same terms. Our team are here to help you get exactly the right solution for your needs and budget.
The ROI of Managed File Transfer
When considering deploying an MFT solution, understanding your potential return on investment (ROI) is crucial. The investment should not only be cost-effective but also deliver measurable benefits to your business. The right solution pays for itself by automating workflows, minimising manual effort, and mitigating security risks.
Your ROI will depend on unique factors such as the size of your organisation and how far along you are in your digital transformation journey. A simple way to calculate ROI is by taking the number of hours spent on manual processes and multiply that figure by the average hourly staff cost. Some of the cost savings to consider include:
- Automating manual processes involving data
- Time saved on help desk support relating to these tasks
- Time spent by technical experts maintaining home-grown scripts and legacy systems
- The risk of a data breach is greatly reduced, along with the associated costs from fines and reputational damage
Is Open Source an Option?
Whilst the open-source marketplace can be a fantastic resource for some business applications, Managed File Transfer isn’t currently one of them. It may be viable if you are a tech business or have an extensive development and technical team. However, for most businesses, Managed File Transfer is mission-critical to mitigate the security and compliance risks associated with supporting a bespoke or homegrown solution. Unmanaged in-house scripts are one of the biggest risks to an organisation’s GDPR compliance.
Additionally, as developers and contractors move on, companies get stuck without documentation, no training and no one to make changes or fix faults. In our experience, large organisations who have implemented open source Managed File Transfer usually revert to a commercial product within a few years. The most common reason they cite is that the functionality was behind the curve of the commercially developed solutions. If you’re still keen to pursue an open source route, start your search with YADE (formerly SOSFTP) and WAARP. Whilst we have been aware of both projects for some time, please note that Pro2col don’t have any affiliation to them or recommend them in any way.
Next Steps
We know it’s difficult to research and select the right Managed File Transfer solution. There are over forty vendors in the marketplace who will naturally want you to choose their product. But MFT underpins your security, efficiency, cloud strategy and digital transformation. These are not areas where you can take risks. You need to research each product thoroughly to choose one that successfully delivers your requirements at the best price.
We have a fantastic array of free resources available to help you with your project. Whichever stage of you are at, you will find useful information that will save you time and money. Just click the links for more details.
Lastly, we think Managed File Transfer is great but it’s not right for every organisation or use case. We’re happy to let companies know if we think there is a better, cheaper, more appropriate way of solving your challenges.
If you would like to dive deeper into the world of secure data exchange, download our comprehensive MFT Guide and learn everything you need to know about managed file transfer software.
Unsure which MFT solution best fits your needs? Take our File Transfer Comparison Quiz for a personalised recommendation.
Have you established that your organisation needs MFT, but can't decided on a solution? Contact one our experts today and we'll be happy to help you find the perfect MFT for your business!
Find the Perfect File Transfer Tool

|
|
The Beginners Guide to Managed File Transfer
Download Pro2col's Definitive Guide for crucial insights about file transfer needs, a review of the marketplace and use case.


|
|
Discover the Best File Transfer Software in 2025
Our experts review the market to reveal the best enterprise-grade file transfer tools available in the current marketplace.


|
|
Get a Personalised File Transfer Recommendation
Take our short 7 minute quiz to discover the perfect file transfer match for your business requirements.

Frequently Asked Questions
The best MFT software completely depends on your organisation's specific needs, such as security, compliance, scalability, and integration capabilities. Leading MFT solutions are widely recognised for their robust encryption and support for protocols like SFTP and FTPS, automated workflows, and regulatory compliance features (HIPAA, GDPR, PCI DSS and SOC 2).
When choosing the best MFT software, it’s essential to consider factors like deployment type (on-premises vs cloud), volume of data transfers, compliance requirements, and ease of integration with existing disparate systems.
To help you, it’s worth checking out our comprehensive, unbiased breakdown of the leading managed file transfer tools and cloud file transfer solutions available in the marketplace today. Our experts keep these pages regularly updated to reflect the latest features, capabilities and developments of each file transfer solution, so you always have the most accurate information when choosing the right MFT platform for your business.
Whilst the open source marketplace can be a fantastic resource for some business applications, Managed File Transfer isn’t currently one of them. It may be viable if you are a tech business or have an extensive development and technical team. However, for most businesses, Managed File Transfer is mission-critical.
It is important to carefully consider your business needs before making a decision on whether to pursue an open source MFT solution.
Advantages of open source MFT:
- Cost: Open source MFT is typically much less expensive than commercial MFT solutions.
- Flexibility: Open source MFT gives you more control over the software and allows you to customise it to meet your specific needs.
- Transparency: Open source MFT allows you to see the source code and understand how the software works. This can be important for security and compliance reasons.
Disadvantages of open source MFT:
- Support: Open source MFT may not have the same level of support as commercial MFT solutions.
- Features: Open source MFT may not have all of the features of commercial MFT solutions.
- Maturity: Open source MFT solutions may not be as mature or reliable as commercial MFT solutions.
Whether or not open source MFT is a good option for you depends on your specific needs and requirements. If you are on a tight budget or need a highly customisable MFT solution, then open source MFT may be a good option for you. However, if you need a high level of support or need an MFT solution with all of the latest features, then you may want to consider a commercial MFT solution.
Yes, open-source managed file transfer (MFT) is an option for organisations looking to securely and efficiently transfer files between systems and users. Open-source MFT solutions are software applications or platforms that allow you to automate, streamline, and secure file transfer processes. They are typically developed and maintained by the open-source community, making them cost-effective and customisable to suit your specific needs.
Some popular open-source MFT solutions include:
- FileZilla: FileZilla is a widely used open-source FTP (File Transfer Protocol) client that supports secure file transfers through protocols like SFTP and FTPS. It's primarily a client application for transferring files, but it's not a complete MFT solution.
- vsftpd (Very Secure FTP Daemon): An open-source FTP server for Unix-like systems that focuses on security. It's commonly used to set up a secure FTP server for file transfers.
- Amanda (The Advanced Maryland Automatic Network Disk Archiver): Amanda is an open-source backup and recovery solution that can be used for transferring files and managing data backup.
- Mule ESB: Although not a dedicated MFT solution, Mule ESB (Enterprise Service Bus) is an open-source integration platform that can be used to build custom file transfer solutions.
- Apache Camel: Apache Camel is an integration framework that can be used to create custom file transfer processes. It supports a wide range of protocols and data formats.
While these open-source options can be effective for certain use cases, it's important to note that they may require more technical expertise to set up and maintain compared to commercial MFT solutions. Additionally, commercial MFT solutions often come with additional features, support, and security measures that can be crucial for enterprise-level file transfers.
Also, one major consideration should be the fact that there are also some security risks associated with using open source MFT solutions. Here are some of the security risks of open source MFT solutions:
- Vulnerabilities in the source code: Open source MFT solutions are typically developed by a community of volunteers, which means that there is no single company responsible for security patching. This can lead to vulnerabilities in the source code that may not be patched promptly.
- Less rigorous security testing: Open source MFT solutions may not be subject to the same level of rigorous security testing as commercial MFT solutions. This can make them more susceptible to attack.
- Lack of vendor support: Open source MFT solutions may not have the same level of vendor support as commercial MFT solutions. This can make it difficult to resolve security issues or get help if you are attacked.
When considering open-source MFT options, it's essential to assess your organisation's specific requirements, including security, scalability, ease of use, and support, to determine whether an open-source or commercial solution is the best fit for your needs.
Managed file transfer (MFT) software is a type of software that helps organisations automate, secure, and manage the transfer of files between different systems and users. MFT software offers a variety of features and benefits, including:
Features:
- Secure file transfer: MFT software encrypts files in transit and at rest to protect sensitive data from unauthorised access.
- Automated file transfer: MFT software can automate file transfer workflows, such as scheduling file transfers at specific times or transferring files based on certain events.
- Centralised management: MFT software provides a centralised console for managing all file transfers, making it easy to track and monitor file transfer activity.
- Audit trails: MFT software generates audit trails that track all file transfer activity, including who transferred what files, when, and where.
- Compliance support: MFT software can help organisations comply with industry regulations, such as HIPAA, PCI DSS, and GDPR.
Benefits:
- Improved security: MFT software helps to improve security by encrypting files in transit and at rest and by providing centralised management and audit trails for all file transfers.
- Reduced costs: MFT software can help to reduce costs by automating file transfer workflows, eliminating the need for manual intervention.
- Increased efficiency: MFT software can help to increase efficiency by streamlining file transfer processes and reducing human error.
- Improved compliance: MFT software can help organisations to improve compliance with industry regulations by providing audit trails and other features that help to track and manage file transfer activity.
Overall, MFT software can offer a number of benefits to organisations of all sizes, including improved security, reduced costs, increased efficiency, and improved compliance.
Here are some additional benefits of managed file transfer software:
- Scalability: MFT software can scale to meet the needs of growing organisations.
- Flexibility: MFT software can be used to transfer files between a variety of different systems and users, including internal and external stakeholders.
- Reliability: MFT software is designed to be reliable and secure, ensuring that files are transferred accurately and on time.
If you are looking for a way to improve the security, efficiency, and compliance of your file transfer processes, then managed file transfer software may be a good solution for you.
Managed File Transfer pricing is going to depend entirely on your requirements, business size and the functionality you opt for. But we can give you an idea, based on products we recommend to our customers.
Costs for a simple automation solution for a small to medium size business start around £3250, plus £600 per year support contract.
A base licence for an enterprise-level Managed File Transfer solution ranges from £10,000 to £50,000 range however we’ve implemented solutions at three times that amount too. Support contracts are typically 20-30% of the licence cost per year, unless you’ve opted for a subscription when support is rolled into the overall annual cost.
Enterprise File Transfer is a software solution that allows the centralised, secure, and automated transfer of files and data within enterprise-level businesses. Often referred to as Managed File Transfer, these software solutions address the growing data movement requirements of large organisations. Unlike basic tools such as free SFTP clients or popular file-sharing apps such as Dropbox or Google Drive, Enterprise File transfer offers more robust tools, with a focus on machine-to-machine data transfers.
Whilst Managed File Transfer is a broad solution set, what identifies it as an enterprise-level software tool is the available features and functionality that are standard requirements within large businesses or organisations. These include:
1) Security and Compliance
As major businesses find themselves needing to comply with growing data legislation and the increased reputational damage of data leaks, enterprise file transfer solutions provide an added layer of security for the critical data processing. From encryption to access controls, auditability and specific adherence to compliance frameworks like GDPR, PCI-DSS, HIPAA, DORA and others, leading file transfer solutions feature robust protections that secure data in transit and at rest.
2) Workflow Automation
Unlike basic transfer tools which focus simply on moving data from one point to another, Managed File Transfer tools built for large global businesses feature significant automation engines that allow for the streamlining of data exchange and the encryption and transfer of files between systems and endpoints. This eliminates the need for manual processing and homegrown scripts, reducing human error and time to deliver increased productivity and cost savings.
3) Visibility and Control
Enterprise organisations, particularly those distributed across multiple sites, countries or regions need to retain visibility on their data flows. Managed File Transfer solutions provide audit reports and can supply notifications when transfers fail, or predicted transfers do not complete.
4) Modular Feature add-ons
One of the key differentiators between basic and enterprise file transfer systems is the feature sets available. The more advanced the file transfer product is, the more likely it will be to have a range of features that will allow even the largest businesses to achieve their goals. Many enterprise transfer tools provide their feature upgrades in module packages, allowing IT teams to select the tooling best suited to their needs.
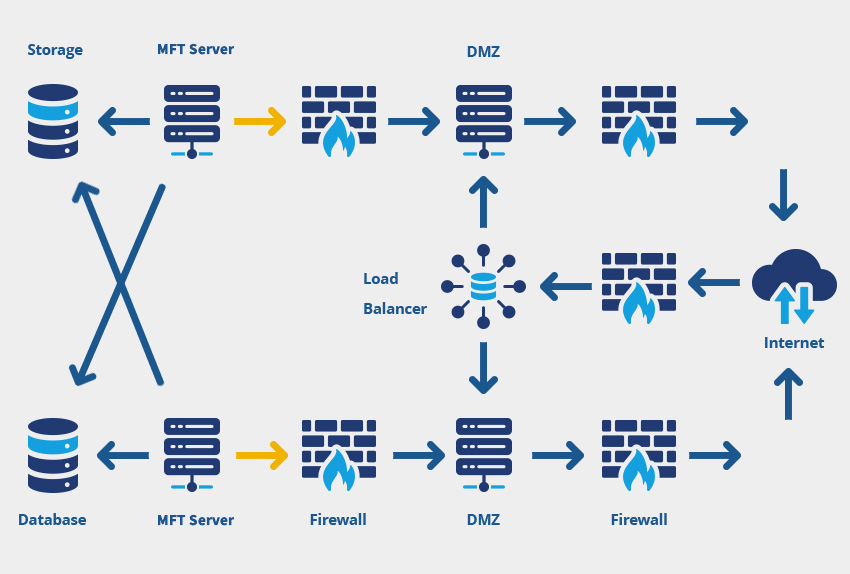
5) High Availability and Disaster Recovery
Lastly, major businesses of today simply cannot risk core systems, like their file transfer software, going down. Enterprise Managed File Transfer tools have options to deliver High Availability in scalable solutions which together with load balancers can virtually eliminate unplanned downtime, ensuring your critical data processes run quickly and efficiently. Disaster Recovery options ensure that if anything does go wrong, that businesses can quickly return to BAU. Enterprise solutions usually also offer follow-the-sun support of their products, ensuring customers have quick, reliable access to support teams for product troubleshooting.